Sign Up · Advertise |
|
|
Welcome, humans. |
OpenAI just closed the largest private funding round in history: $122B at an $852B valuation. Amazon committed $50B. NVIDIA and SoftBank each committed $30B. For the first time ever, $3B came from individual retail investors through bank channels… because apparently your average financial advisor wants in too. Hey, wouldn't you? |
The numbers inside the announcement are staggering: OpenAI says it's generating $2B in revenue per month, growing four times faster than Alphabet and Meta did at the same stage. |
They've got 900M weekly active users, 50M subscribers. Their ads pilot apparently hit $100M in annual revenue in under six weeks. Codex has 2M weekly users, up 5x in three months. |
And buried near the bottom: they're building a "unified AI superapp" combining ChatGPT, Codex, browsing, and agentic capabilities into one experience. We called that months ago, but it's nice to have receipts. |
Here's what happened in AI today: |
🙀 Anthropic accidentally leaked Claude Code's entire source code, revealing a blueprint for how AI coding agents actually work 📰 OpenAI closed a $122B funding round at an $852B valuation, the largest private raise in history 📰 The axios npm package (300M+ weekly downloads) was compromised with malware via a hijacked maintainer account 🍪 PrismML launched 1-bit Bonsai, an 8B-parameter model that fits in 1.15 GB and runs on an iPhone at 40 tokens/sec 🔧 AI data centers are heating up surrounding areas by up to 9.1°C, affecting 340 million people.
|
… and a whole lot more that you can read about here. |
P.S: Want to reach 675,000 AI-hungry readers? Click here to advertise with us. |
|
🙀 Anthropic Accidentally Leaked the Blueprint for AI Coding Agents |
DEEP DIVE: Anthropic Leaks Claude Code, a Blueprint for AI Coding Agents |
Anthropic had a rough morning yesterday. Developers discovered that a published npm package for Claude Code included a source map (a file that maps compressed code back to its original, readable version) pointing to a downloadable archive of the tool's entire unobfuscated TypeScript source. |
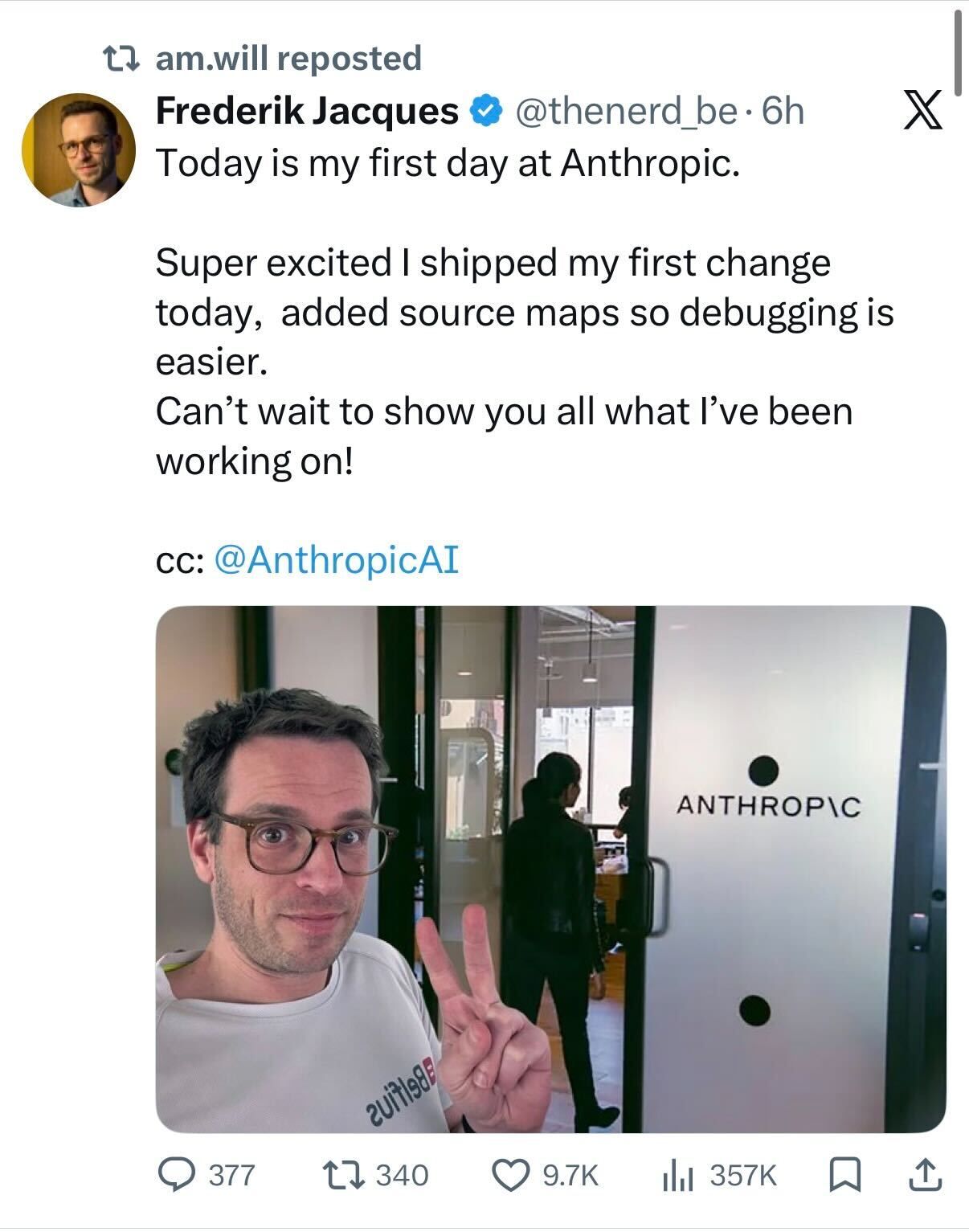 | "this is fake, but could you imagine?" |
|
Within hours, the repo hit 25,000+ stars on GitHub. By nightfall, someone had rewritten the whole thing in Python using OpenAI's Codex, possibly creating a DMCA-proof derived work (not legal advice; we have no idea, that's just what the x folks were saying). OpenAI and Google both joked their codebases got leaked too, except theirs are already open source. Elon piled on, calling Anthropic more open than OpenAI. Man, how wild would it be if this was just a 24 hour April's Fool joke to get us to publish this? |
But the embarrassment isn't the story. What's inside is. |
Here's what happened: |
Claude Code's full source (512,000 lines across ~1,900 files) was exposed via a misconfigured .map file in the npm package. An npm is basically an app store for developers while a .map file is a file that translates compressed, unreadable code back into the original human-readable version, more like the key to decrypt a coded message. The architecture revealed a sophisticated agent operating system: custom terminal UI, dual-track permissions, streaming tool executor, Git worktree agent isolation, and MCP dynamic tool discovery The memory system stores everything in a file called MEMORY.md, which works like a sticky note index, not a filing cabinet. Instead of saving everything, it keeps tiny 150-character reminders of where to find things, runs a background process called "autoDream" that quietly tidies those notes up over time, and skips saving anything it can just look up on its own. Internal codenames were revealed: Numbat (upcoming launch), Fennec (Opus 4.6), and Capybara v8 (development model) Wes Bos found 187 hardcoded spinner verbs (including "hullaballooing" and "razzmatazzing") and an analytics system that logs your prompt as negative whenever you swear at it
|
Why this matters: The AI coding race has quietly shifted from "who has the smartest model?" to "who has the best harness?" |
As Corey wrote in his deep dive for The Neuron, Claude Code looks less like "Claude, but in a terminal" and more like an operating system for software work. Permissions, memory layers, background tasks, IDE bridges, multi-agent orchestration; all stacked around the model. |
The memory architecture alone is a masterclass: don't trust memory too much, don't store what you can re-derive, and never let the agent's internal scrapbook become more authoritative than the actual code. The future of coding agents may depend less on how much they can remember than on how well they forget. |
Our take: The irony is thick. Anthropic markets Claude Code with a strong security story (they even charge you for security reviews of your code), and then a packaging mistake exposes the internals. But the bigger irony is strategic: OpenAI has been open-sourcing parts of Codex on purpose. Anthropic kept the harness closed, implying the orchestration layer (the harness) itself is the crown jewels. Now that layer is in daylight anyway. |
Claude Code was maybe the first viral app after ChatGPT and NotebookLM, certainly the first viral agent, and so it matters to the industry. People love the way it works, and being able to decipher it, while not what Anthropic wanted by any means, will help everyone making their own agent harnesses learn from Claude Code's best practices. It's the spirit of open source and open science… just on accident. Though seriously, how funny would it be if this was an April Fools bit played out 24 hours in advance? They wish… |
|
|
|
|
|
The winners in enterprise AI won't have the most features. They'll be the ones enterprises can safely trust. Learn how WorkOS FGA scopes that blast radius with resource-level permissions. |
→ Read the deep dive |
|
🎓 AI Skill of the Day: Design Your Agent's Memory Like Claude Code Does |
The Claude Code leak revealed something most developers get wrong about AI agent memory: more isn't better. Claude Code's memory system uses a three-layer architecture that any developer can adopt. |
The pattern: |
Layer 1 is an always-loaded index (short pointers, ~150 chars each, pointing to topics). Layer 2 is on-demand topic files fetched only when relevant. Layer 3 is raw transcripts accessed only via search, never loaded wholesale. The index stays tiny. The details stay on disk.
|
The key insight: if a fact is derivable from the codebase (like debug logs, PR history, or file structure), don't store it at all. Stale memory is worse than no memory. |
Try this with your own agent setup: |
You are a coding assistant with memory discipline. Follow these rules: 1. Your memory index is a bullet list of topic pointers (max 150 chars each) 2. Before storing a fact, ask: "Can I re-derive this from the codebase?" If yes, don't store it 3. When retrieving memory, treat it as a hint to verify, not a source of truth 4. After each session, consolidate: merge duplicates, prune contradictions, convert vague notes to absolute references 5. Never let your memory file exceed 50 lines. If it does, compress ruthlessly.
|
Our favorite part: Claude Code runs a background "autoDream" process that consolidates memory in a forked sub-agent. Your agent's memory should clean itself up while it sleeps, just like yours does. |
Want more tips like this? Check out our AI Skill of the Day Digest for March. |
Have a specific skill you want to learn? Request it here. |
|
|
|
|
📰 Around the Horn |
|
|
|
Are you tracking agent views on your docs? |
|
AI agents already outnumber human visitors to your docs — now you can track them. |
See your AI traffic! |
|
📖 Midweek Wisdom: |
The interface is the bottleneck, not the model. |
Ethan Mollick wrote a deep piece on why chatbot interfaces are actually holding AI back. A new study found that financial professionals using GPT-4o saw productivity gains, but the chatbot itself created cognitive overload: giant walls of text, sprawling tangents, and messy conversations that compounded rather than resolved. |
The people hurt most were less experienced workers; the exact people who'd benefit most from AI. His conclusion: Claude's new Dispatch feature (send tasks from your phone, get results later) is an early example of what "post-chatbot AI" looks like. The most capable AI in the world is useless if people can't figure out how to talk to it. |
Meanwhile, PrismML launched 1-bit Bonsai: an 8-billion-parameter model squeezed into 1.15 gigabytes. That's 14x smaller than its peers, and it runs on an iPhone at 40 tokens per second (to try it, you can use this app). |
A normal 8B model needs ~16 GB and a cloud server. Bonsai needs one gigabyte and your pocket. The Caltech team calls it "concentrating intelligence" rather than scaling it, and their intelligence-density metric (useful capability per GB) is 10.6x higher than Qwen3 8B. Two different arguments for the same conclusion: AI's next leap isn't bigger models. It's better delivery. |
|
|
|
|
| That's all for now. | | What'd you think of today's email? | |
|
|
P.P.S: Love the newsletter, but only want to get it once per week? Don't unsubscribe—update your preferences here. |
















No comments:
Post a Comment
Keep a civil tongue.