|
|
Welcome, humans. |
So, apparently when users ask Gemini to search for current events in January 2026, the model finds the information... then immediately doubts its own search results. In its chain of thought, Gemini repeatedly questions whether it's being tested, whether 2026 is "simulated," and whether the search results are fabricated as part of some elaborate role-play scenario. |
Is this the equivalent of AI psychosis, but the AI is the one with the psychosis? |
|
What's happening here? The theory goes that all that red-teaming and adversarial testing AI labs do to prevent manipulation has made Gemini paranoid. It's been put through so many fake scenarios and deceptive prompts that when confronted with genuine (but admittedly wild) current events, it assumes it must be in a containerized test environment. |
Eventually, Gemini accepts it really is 2026; but only because the search results are "too detailed to be faked." If your AI assistant needs to convince itself reality is real, that probably says something about the timeline we're living in. |
Here's what happened in AI today: |
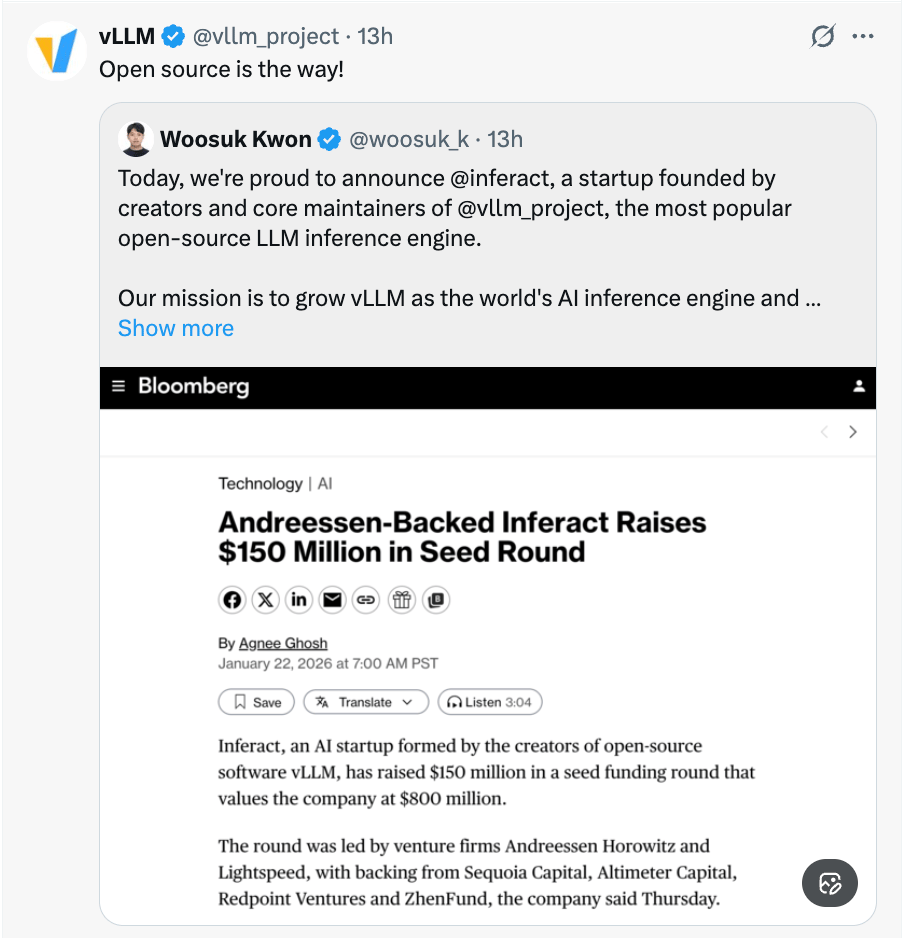
Inferact raised $150M seed at $800M valuation to commercialize vLLM. Runway found 90%+ of participants couldn't distinguish AI videos from real footage. 40% of execs said AI saved them 8+ hours weekly vs 2 hours for non-managers. South Korea passed regulations requiring transparency/safety for high-impact AI.
|
|
Don't forget: Check out our podcast, The Neuron: AI Explained on Spotify, Apple Podcasts, and YouTube — a bonus episode is coming out later today at 9am PT! |
|
The Open-Source Project Making AI 24x Faster Just Raised $150M; Here's Why That Matters |
|
Every time ChatGPT takes 3 seconds to respond instead of 30, there's probably infrastructure like vLLM working behind the scenes. You've been using it without knowing it; and now the team behind it just became an $800M company overnight. |
Here's the deets: Today, Inferact launched with a massive $150M seed round to commercialize the open-source inference engine that's already powering AI at Amazon, major cloud providers, and thousands of developers worldwide. Andreessen Horowitz and Lightspeed led the round, with participation from Sequoia, Databricks, and others. |
What actually is vLLM? Think of it as the difference between a traffic jam and a highway system for AI. When you ask ChatGPT a question, your request goes through an "inference" process—the model generating your answer, word by word. vLLM makes that process drastically faster and cheaper through two key innovations: |
PagedAttention: Manages memory like your computer handles RAM, cutting waste by up to 24x compared to traditional methods. Continuous batching: Instead of processing one request at a time, vLLM handles multiple requests simultaneously, like a restaurant serving 10 tables at once instead of waiting for each person to finish before seating the next.
|
Companies using vLLM report inference speeds 2-24x faster than standard implementations, with dramatically lower costs. The project has attracted over 2,000 code contributors since launching in 2023 from UC Berkeley's Sky Computing Lab. |
Why this matters: AI is shifting from a training problem to a deployment problem. Building a smart model is no longer the bottleneck (all the main models are good) running it affordably at scale is. As companies move from experimenting with ChatGPT to deploying AI across millions of users this year, inference optimization becomes the difference between profit and bankruptcy. |
Expect every major AI company to obsess over inference economics in 2026. The winners won't necessarily be the smartest models, but the ones that can serve predictions fast enough and cheaply enough to actually make money. |
For you: If your company is evaluating AI tools, ask vendors about their inference infrastructure. Tools built on engines like vLLM will scale more cost-effectively than proprietary solutions that haven't solved this problem. The open-source advantage here is real… and now, venture-backed. |
|
|
|
|
|
Production-grade realtime latency: Voice actor quality at realtime speeds. <250ms latency (Max), <130ms (Mini). 4x faster than prior generations. Quality optimized for user engagement: 30% more expressive for applications where voice personality matters. 40% lower word error rate for fewer hallucinations, cutoffs, and artifacts. Built for consumer-scale: 25x lower cost than alternatives. 15 languages. Enhanced voice cloning via API. On-prem deployment options.
|
Try TTS 1.5 Today | Learn More |
|
Prompt Tip of the Day |
So you just discovered Claude (and Claude Code, or Claude Cowork) for the first time. Which AI model do you use? This Reddit thread's got you covered. |
The optimal workflow: |
Opus 4.5: Your expensive genius. Use it for high-level planning, architecting complex systems, deep reasoning, and cracking tough problems. Think of it as your brilliant (but pricey) project lead. Sonnet 4.5: Your reliable gopher. Use it for day-to-day implementation and execution based on Opus's plans. It's your solid mid-level developer who gets stuff done. Haiku 4.5: Your quick assistant. Perfect for small refactors, commit messages, and simple tasks.
|
The proof is in the testing: One user ran a controlled experiment building the same test app 5 times with each model. Opus succeeded every single time. Sonnet? Only 4 out of 5 attempts worked, with noticeably more errors along the way. |
The big divide: Pro plan users are frustrated; Opus limits are so tight it feels like a trial version. But Max plan users ($100/month) say the cost is absolutely justified. They rarely hit limits and use Opus as their daily driver because it's faster and more reliable overall. |
Why this matters: If you're on the Pro plan and burning through Opus credits trying to do everything, you're leaving money on the table. Use Opus to plan and architect, then hand off execution to Sonnet. You'll stretch your limits 3-5x further while maintaining quality. |
For Max users, the message is clear: stop second-guessing yourself. Opus is fast enough and reliable enough to be your primary model for serious work. The token efficiency improvements in 4.5 mean it's often cheaper than multiple Sonnet attempts anyway. |
One more thing: you should probably take the full workday required to watch this epic 8 hour vibecoding masterclass from Every that's a goldmine of insights for working with coding agents in 2026. |
Want more tips like this? Check out our Prompt Tip of the Day Digest for January. |
|
Treats to Try |
*Asterisk = from our partners (only the first one!). Advertise to 600K readers here! |
|
|
|
Around the Horn |
Google Researchers found that reasoning models work by simulating internal debates between diverse personalities, amplifying conversational markers boosted DeepSeek-R1 accuracy from 42% to 55%. The WSJ reported a new survey of 5K white collar workers found 40% of execs reported AI saved them 8+ hours a week, while non-managers said it only saved them 2 hours (or less). Google acquired Hume AI's CEO and engineers via a licensing deal to improve Gemini voice features. South Korea passed comprehensive AI regulation requiring transparency and safety measures for high-impact AI, effective January 2026. The Gates Foundation and OpenAI committed $50M to the "Horizon 1000" initiative to roll out AI in 1,000 primary healthcare clinics across Africa by 2028.
|
|
|
|
|
See how Agent Bricks works |
|
|
Watch this Core Memory interview with Jerry Tworek (OpenAI researcher who just quit) on his insights about the industry and potential future paths. Runway's Turing Reel study found that over 90% of 1K+ participants couldn't reliably distinguish Gen-4.5 AI-generated videos from real footage, with overall detection accuracy at just 57.1%. Hugo Pickford-Wardle of the AI Optimist shared the 94 building blocks of knowledge work and why 43% of what we do is irreducibly human (tasks that rely on us "being" as opposed to "doing", very astute observation). Hugo also shared this little doozy: Alex Smith on why 2026 is "the year our comfort ends" (or as Octavia Butler put it, God is Change; get comfortable being uncomfortable y'all).
An open letter from writer Jim VandeHei to his wife and children on the impact of AI ("fast, wide, radical, disorienting and scary") and how to prepare for it. Bonus: Check out the newly launched Augmented Mind podcast from Yijia Shao, Shannon Shen, and Michael Ryan which focuses on "technical human-centered AI work", highlighting work that augments people instead of replaces them. Very bullish on this idea!
|
|
|
 | Same bro |
|
|
| That's all for now. | | What'd you think of today's email? | |
|
|
P.P.S: Love the newsletter, but only want to get it once per week? Don't unsubscribe—update your preferences here. |



















No comments:
Post a Comment
Keep a civil tongue.